
Inside the Black Box of LLM Training Data: What the FineWeb Paper Reveals About Getting Into a Model’s Memory

Inside the Black Box of LLM Training Data: What the FineWeb Paper Reveals About Getting Into a Model’s Memory
What a 15-trillion-token paper reveals about getting into a model's memory.
 Ian Sorin
June 20, 2026
13 min read
Ian Sorin
June 20, 2026
13 min read
11 min read
- Common Crawl is just the raw material. It is a free, public copy of the web. In FineWeb, the team re-filtered it heavily before training, so being crawled is not the same as being in a model's memory.
- From web page to training data is a heavy funnel: clean the text, keep one language, drop low-quality pages, remove duplicates. In FineWeb, most of the web is thrown away on purpose.
- FineWeb used simple, mechanical rules to drop pages: too few real sentences, too many short or duplicated lines, boilerplate, adult URLs. Plain, well-written, original text is what survived. Other labs probably do something similar, but the exact rules are their own.
- For their best version, FineWeb used another AI to grade pages (Llama-3-70B scored them and only the good ones were kept). "Good = educational" was their choice; the bigger signal is that an AI now does the sorting.
- Scale check: FineWeb alone is 15 trillion tokens, and the big labs use even more. One page is a drop in the ocean, which changes how you should think about "getting into the training data".
"How do I get ChatGPT to mention my brand?" I get some version of that question almost every week, and it is a fair one.
The honest answer is that there are only two ways into an AI's answer, and most people only ever think about one of them.
Door one is live retrieval. The chatbot runs a search while it answers you, grabs a few pages off the live web, and writes its reply from those.
We actually know a fair bit about this door: which search engines power which assistants, the queries they fire off, the sources they show. It leaks signal, and you can work with it.
I do exactly that in my GEO process and my server log work.
Door two is the model's own memory. When an AI answers without searching, it pulls from what it absorbed while it was being trained.
If your brand or your point of view is baked deeply enough into that training data, you show up "for free", with no live search at all.
This is the door everyone wants, and the one almost nobody understands. The training datasets behind ChatGPT, Gemini or Llama are completely secret, and the companies tell us almost nothing about how they were built.

So when a team publishes its full recipe in the open, you read it. That team is Hugging Face, and the dataset is called FineWeb.
It is 15 trillion tokens of text pulled from the public web, documented from start to finish. (A "token" is roughly a word, or a piece of a word, so picture a genuinely enormous pile of writing.)
One honest caveat before we start, and I will repeat it: FineWeb is not the dataset behind ChatGPT or Gemini. Nobody outside those labs has seen those.
FineWeb is the best public example we have, and a useful stand-in, but everything below is what one specific team chose to do.
Read it as a strong hint about how the big players probably work, not as proof of what they actually do. With that said, let's go through it slowly and in plain language.
The journey: from the open web to one piece of training data
Before we dig in, here is the whole FineWeb pipeline in a single picture.
The thing to notice: every step exists to delete data. The web goes in huge and comes out much smaller.
the raw open web, billions of pages
starting point
keep the main content, drop menus and clutter
English only, in FineWeb's case
simple rules on punctuation, line length, repetition
collapse copy-paste and near-identical pages
First, what is Common Crawl (and why does every project start there)?
The whole thing rests on this, so let me explain it simply. Common Crawl is a non-profit that has been crawling the public web since 2008 and giving the results away for free.
Every month or so it publishes a fresh "snapshot": a big copy of billions of web pages. FineWeb is built from 96 of these snapshots, going back from 2024 all the way to 2013.
Why does everyone start there? Because it is the biggest free copy of the open web that exists, already crawled and ready to download.
If you need trillions of words and you do not want to run a planet-sized crawler yourself, Common Crawl is the obvious starting point.
That is also exactly why it matters to you: if a crawler cannot reach your page, you are not even in the raw pile, let alone the final dataset. (More on this in How Google Crawls the Web.)
Lesson 1: Common Crawl is not the training data
Here is the first big takeaway, and the most useful one for anyone doing GEO: the FineWeb team did not train on raw Common Crawl.
Raw, the web is too noisy and too full of spam to be useful. So they cleaned and filtered it heavily first.
How do we know it was worth the effort? They ran what researchers call an "ablation", which just means a controlled before-and-after test.
They trained one small model on the filtered data and an identical one on the unfiltered data, then compared the two. The filtered version won clearly.
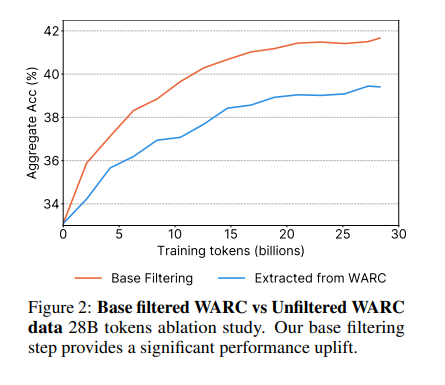
So the thing to remember: being crawled by Common Crawl is not the same as being in the training set. Getting crawled puts you in the raw pile.
After that, a long series of filters decides whether you actually make it through. In FineWeb, most pages did not.
The four filters a page had to survive in FineWeb
1. Cleaning the text: only your main content counts
A web page is messy underneath: menus, sidebars, cookie banners, footers, buttons. FineWeb ran a tool that pulls out just the main body text and throws the rest away.
(They compared this to Common Crawl's ready-made text version, and their cleaner extraction trained a better model.)
Why this matters to you: the text that ends up "being" your page, as far as the model is concerned, is the body of your article, not your header, your menu or your buttons.
If your real substance is hidden inside tabs, accordions or fancy widgets instead of plain body text, it can get stripped out before training even begins.
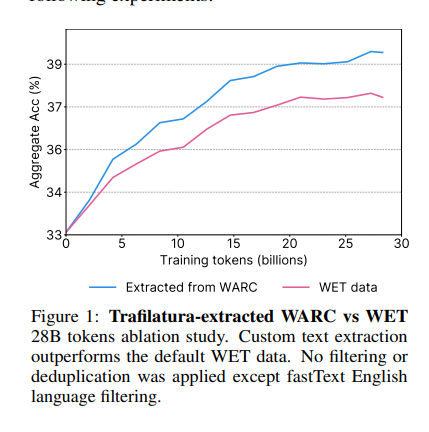
2. Language: a choice, not a law
Next, FineWeb kept only English pages, using an automatic language detector with a confidence cut-off. Let me not oversell this one, because it is easy to over-read.
All it really tells us is that this particular dataset chose to focus on English and dropped the rest.
It does not mean other languages are missing from the AIs you use every day. ChatGPT, Gemini and the rest are very much multilingual, trained on plenty of non-English text through other pipelines.
What we can safely say is that English is heavily favoured (more data, stronger scores). How much real weight the other languages carry is genuinely an open question, and a fascinating one.
The honest takeaway is narrow: when a team wants a clean, focused dataset, language is one lever they can pull, and FineWeb pulled it all the way to English.
3. Quality rules: the step that removes the most
This is where it gets concrete. FineWeb started from filter lists invented by earlier datasets (with names like C4 and Gopher).
Then they added three rules of their own, found by comparing good pages and bad pages and seeing what told them apart. We will list the actual rules in the next section, because that is the part you really want to see.
4. Removing duplicates: the original survives, the copy does not
Finally, they removed near-duplicate pages: copy-paste, syndicated articles, content scraped and reposted elsewhere.
They used a technique (called MinHash) that is good at spotting two pages that are mostly the same even if they are not identical. One copy is kept, the rest are dropped, so the original survives and the echoes do not.
But the paper turns up a counter-intuitive result worth pausing on, because more de-duplicating was not actually better.
You would expect that removing more duplicates is always good. In FineWeb, it was not. When they removed duplicates across all 96 monthly snapshots at once, the models barely improved, and on the oldest snapshots they actually got worse.
The reason is sneaky: that aggressive pass keeps whatever appears only once and deletes everything that repeats. But on old crawls, what survives is mostly odd, low-quality, never-repeated junk.
They even checked by training two models, one on the pages they kept and one on the pages they removed. The removed pages trained the better model.
So they switched to removing duplicates inside each snapshot separately, which kept about 20 trillion tokens and worked better. The point: being unique is not the same as being good. You want original and well-made.
Lesson 2: the actual list of what got dropped (and what stayed)
You wanted the exhaustive version, so here it is, with one important framing first: this is FineWeb's list, from their experiment.
It is not an official rulebook that every AI follows. Treat it as a concrete, real example that gives us a good idea of the kind of thing other teams probably do too.
In FineWeb, these are the kinds of rules that quietly dropped a page (or part of it). None of them are clever. They are simple and mechanical.
- Pages with very few lines that end in real punctuation
- Too many repeated lines on the same page
- Too many very short lines (link lists, menus, navigation dumps)
- Pages that are too short, or strangely long
- The same words and phrases repeated over and over
- Filler like "lorem ipsum", "please enable JavaScript", cookie notices
- Lines that look like code rather than writing
- Web addresses on an adult-content blocklist (whole sites)
- Pages that are near-copies of something already kept
- Text written in real sentences, with normal punctuation
- Proper paragraphs, not walls of one-liners
- Enough substance (not a thin, empty page)
- Little internal repetition
- Original writing, not a copy of someone else's
- Clean main content, light on clutter
- A safe, non-blocklisted website
A couple of details that say a lot. One old rule (from the C4 dataset) simply deletes any line that does not end with punctuation. On its own, that one rule throws away about 30% of all the text.
The FineWeb team kept the rest of the C4 rules but dropped that one, and got better results while cutting far less.
Their three new rules (too few properly-punctuated lines, too many characters inside duplicated lines, too many very short lines) together remove around 22% of the text.
You do not need to memorise any of this. The shape is the point: writing made of real sentences survives, while broken, repetitive, list-like content gets dropped.
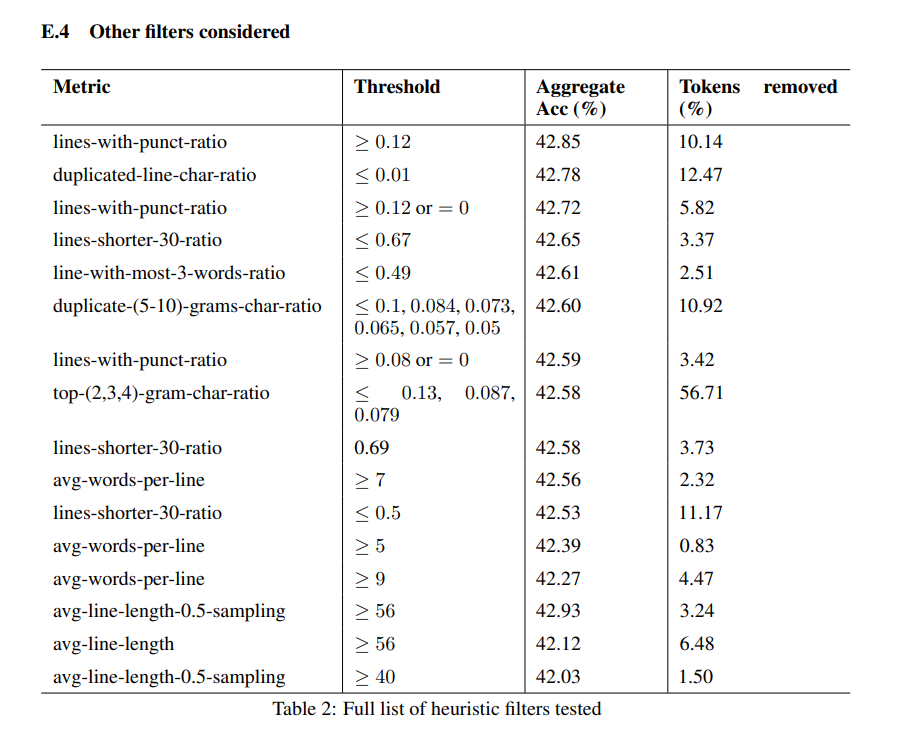
If you want to see the raw thing, here is their full table of candidate rules.
You really do not need to read every row: each line is one filter, the cut-off they used, and how much of the data it deletes. The only takeaway is how many small, mechanical rules a page has to pass.
Lesson 3: in their best version, an AI graded the content
This is the part that should interest every content marketer. For their top-quality version (called FineWeb-Edu), the team did not write more rules by hand. They had an AI do the judging.
Here is what they did, in plain terms. They took a large AI model (Llama-3-70B), showed it about 460,000 web pages, and asked it to score each one from 0 to 5 on how "educational" it was.
Then they trained a small, cheap program to copy that scoring across all 15 trillion tokens, and kept only the pages that scored 3 or higher.
What is left, about 1.3 trillion tokens, is the cream skimmed off the top by an AI.
And it worked surprisingly well. That smaller, AI-selected set trained models that beat the full dataset on knowledge tests, while using only a fraction of the data.
(The main test here is called MMLU: a big multiple-choice exam across loads of subjects, used to measure how much a model actually "knows".)
One important nuance, because this is easy to over-read: FineWeb-Edu chased educational value because that is the kind of model the authors wanted, strong on knowledge and reasoning.
That specific choice is theirs, not a rule every lab follows. So please do not walk away thinking "I must write like a textbook to get into ChatGPT".
A different team might score for code, or conversation, or safety, or sheer variety.
The part that probably does carry over is one level up: more and more, the gatekeeper is an AI scoring your content against some quality bar. The bar itself changes from lab to lab, but the fact that an AI can do that grading cheaply, across the whole web, is what looks here to stay.
Lesson 4: do my few pages even matter?
Let's be honest, because the scale is humbling. FineWeb is 15 trillion tokens, and remember, that is the open, "small" reference dataset. The big labs train on even more.
Next to a number like that, a website publishing a handful of pages is, mathematically, a rounding error.
So should you give up? No, but you should change the goal. You are not going to tip a 15-trillion-token ocean with one article, and chasing that is what leads people to spammy nonsense.
A more realistic reading is that two things plausibly matter at this scale.
First, simply being eligible: clean enough, original enough, well-written enough, on a safe site, so your content is even allowed into the pile in the first place.
Second, being repeated and confirmed: the same idea or association showing up across many pages and many sites over time, so the signal is strong enough to survive de-duplication and be learned as a pattern, not noise.
One page is a drop. A solid, consistent body of content that the rest of the web keeps echoing is a current.
So what does this actually tell us?
We started with two doors into an AI's answer. The live-search door, we can study. The training-data door has always been closed.
This one paper does not hand us the big labs' keys, but it does switch on a light in a room we usually only guess about, and the layout in there is probably similar from one lab to the next.
I am not going to turn this into a ten-step checklist, because honestly the paper does not support one. Take it instead as a handful of "oh, so that is roughly how it works" realisations.
A few things worth keeping in mind: being crawled is only the entrance, not the destination. Your main body text is what counts, not the design around it.
Clean, well-written, original writing is what survives a wall of simple filters. And in FineWeb's best version, an AI is the one that decided what was good enough.
Again, all of this is one team's recipe, not a universal law, and I would rather under-claim than pretend otherwise. But when the big labs share nothing at all, a fully documented public example is the best map we have.
That's all for today. Bye!

Ian Sorin is an SEO consultant based in Lyon, France. With a deep passion for understanding how search engines (and now language models) work under the hood, he specializes in technical SEO and data-driven strategies.





