
How Google Crawls the Web: The Complete Technical Guide

How Google Crawls the Web: The Complete Technical Guide
The complete technical guide: crawl budget, scheduling, rendering.
 Ian Sorin
January 25, 2026
21 min read
Ian Sorin
January 25, 2026
21 min read
Updated: March 2026
Hey, it’s Ian !
Are you sure you know everything about Google crawl ? Really everything ?
Today I’m sharing everything I know about how Google crawls the web. We’ll cover the technical process, crawl budget, predictive crawling (yes, Google now predicts if your page is worth visiting), and a hidden rule that causes pages to get deindexed after a specific number of days.
Fair warning : this is dense. But if you’re serious about technical SEO, bookmark this one.
Let’s dive in.
- Crawling comes before everything: no crawl = no indexing = no ranking
- Crawl budget = crawl rate (how fast) + crawl demand (how much Google wants your content)
- Google now uses predictive crawling: ML decides if your page is worth visiting BEFORE crawling
- The 130-day rule: pages not crawled for 130 days get removed from the index
- Content freshness matters: regularly updated sites get crawled more often
- Nofollow doesn’t prevent crawling: it only affects PageRank flow
- User data can influence Crawl Rate.
I. The Crawling Process: Step by Step
Before we get into the advanced stuff, let’s make sure we’re aligned on how crawling actually works.
“Hi! I’m Googlebot. Let me show you how I explore the web and decide which pages deserve to be in Google’s index. It’s more complex than you think!”
🔄 The Crawl Journey: From Discovery to Indexing
Click on each step to learn more about what happens (and what can go wrong)
🔍 Step 1: URL Discovery
Google finds new URLs through multiple sources: following links from already known pages, reading your sitemap, or from external links pointing to your site.
- Internal links from crawled pages
- XML sitemaps
- External backlinks
- Google Search Console URL submission
- Orphan pages (no internal links pointing to them)
- Missing or broken sitemap
- Noindex on linking pages
- Pages too deep in site architecture
1.1 URL Discovery
The web is massive. We’re talking trillions of URLs out there.
Google’s crawling process begins with a list of web addresses from previous crawls and sitemaps provided by site owners. From there, Google follows links on those pages to discover new URLs.
Not all pages get discovered. And not all discovered pages get crawled. Google has to make choices because even their resources aren’t infinite.
1.2 How Googlebot Works
Googlebot is Google’s main crawler software. Think of it as a very sophisticated browser that visits web pages, reads their content, and follows links.
Every decision Googlebot makes is algorithmic, there’s no manual intervention deciding which pages to visit. Instead, it relies on signals and machine learning to prioritize what matters most.
Here’s what Googlebot handles automatically:
- Scheduling decisions: which sites to crawl and how often, based on historical value and freshness signals (and user data)
- Volume management: how many pages to fetch from each site without exhausting resources
- Politeness controls: managing load to avoid overloading your servers (Google genuinely tries to be a good web citizen)
- Change detection: revisiting pages periodically to check if content has been updated
1.3 Fetching & Rendering
It’s important to distinguish between two types of actions within this infrastructure:
- Crawlers: They work in batches, processing a constant stream of URLs continuously. This is the ‘standard’ Googlebot activity.
- Fetchers: These handle URLs individually. When you use the ‘URL Inspection’ tool in Search Console, you’re triggering a Fetcher, not the main crawler. It’s a surgical, one-time request.
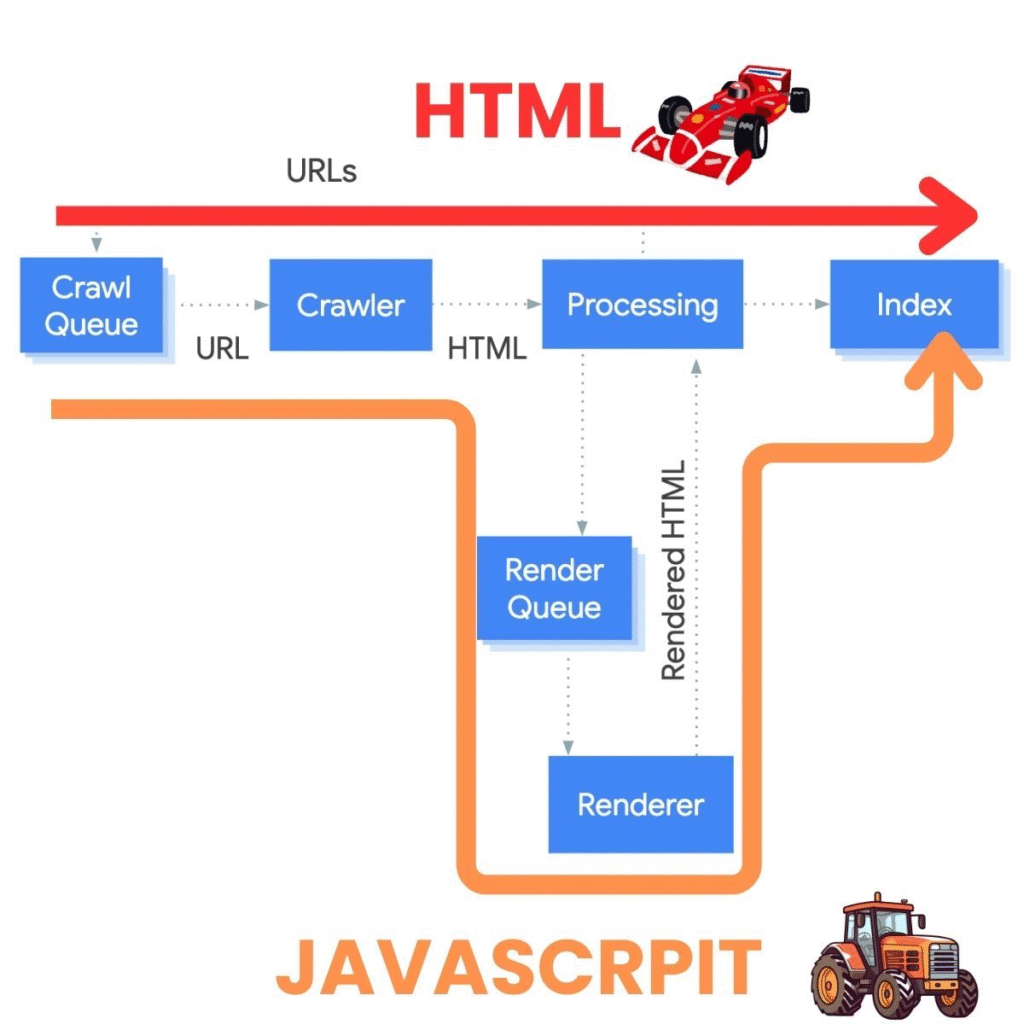
So after Crawling there is two distinct operations:
Fetching = downloading the page data (HTML, resources)
Rendering = using a headless Chrome browser to turn HTML, CSS, and JavaScript into the visual representation of the page
This matters a lot for JavaScript-heavy sites. If your content is rendered client-side, Google needs to execute that JavaScript to see what’s actually on the page.
And did you know Googlebot has a “download limit”?
To keep the web efficient, according to google official statement Googlebot doesn’t read infinitely large files. For most web pages and scripts, it only looks at the first 2MB of data. If you’re hosting PDFs, the limit is much higher at 64MB.
Why does this matter? > Once Googlebot hits that limit, it simply stops downloading and only indexes the part it has already seen. This applies to the “uncompressed” size of your files, meaning the actual weight of your code, not the zipped version your server sends.
This rule also applies to your CSS and JavaScript files. If your scripts are too heavy, Google might only see a portion of them, which can break how your site is rendered. Keep your files lean to ensure Googlebot gets the full picture!
1.4 The Role of Sitemaps
Sitemaps are XML files that list your URLs and tell Google “hey, these pages exist.”
Are they mandatory? No.
Are they highly recommended? Absolutely.
Sitemaps help Google discover pages that might be hard to find through internal linking alone. They also provide metadata like when a page was last modified.
Best practice : Let your CMS generate sitemaps automatically. WordPress, Shopify, and most modern platforms do this out of the box.
II. Crawl Budget: What It Is and Why It Matters
This is where things get interesting.
“I can’t visit every page on the internet, I have limits too! My ‘crawl budget’ determines how many pages I can visit on your site. Let me explain how it works…”
2.1 Defining Crawl Budget
Crawl budget is made up of two components:
Crawl Rate = the maximum number of concurrent connections Googlebot can use to crawl your site. This is calculated based on your site’s responsiveness. Fast site = higher crawl rate. Slow site = lower crawl rate.
Google’s infrastructure is built to ‘not break the internet.’ If your server returns a 503 (Service Unavailable), the crawler doesn’t just stop; it drastically slows down its entire cadence for your host, assuming your server is overwhelmed. It can take a long time for the crawl rate to return to normal after a 503 spike.
Crawl Demand = how much Google wants your content. This is affected by:
- URLs that haven’t been crawled before (new content)
- Google’s estimation of how often your content changes
- The perceived quality and popularity of your pages
It’s the number of URLs Google can AND wants to crawl on your site.
2.2 When Does Crawl Budget Actually Matter?
I often see consultants and agencies talking about “crawl budget” for websites with fewer than 5,000 pages.
At that scale, these sites are tiny compared to the size of the web, and crawling them entirely is absolutely not a problem for Google (assuming the site is worth crawling in the first place).
Crawl budget only becomes a real issue when a website reaches hundreds of thousands of pages, and more realistically, millions, according to Google representatives themselves.
So if someone warns you about your crawl budget for a small website, be cautious: your provider may not really know what they’re talking about.
For smaller sites, the focus should be on crawl demand. If your content hasn’t changed in a year, Google might decide to only recrawl it every two weeks instead of every day.
2.3 HTTP Status Codes & Crawl Budget
Not all HTTP responses are equal when it comes to crawl budget. Here’s how different status codes impact your crawling:

2.4 Search Console Crawl Stats Report
Want to see how Google actually crawls your site? The Crawl Stats report in Search Console is your friend.
Where to find it: Settings > Crawl Stats
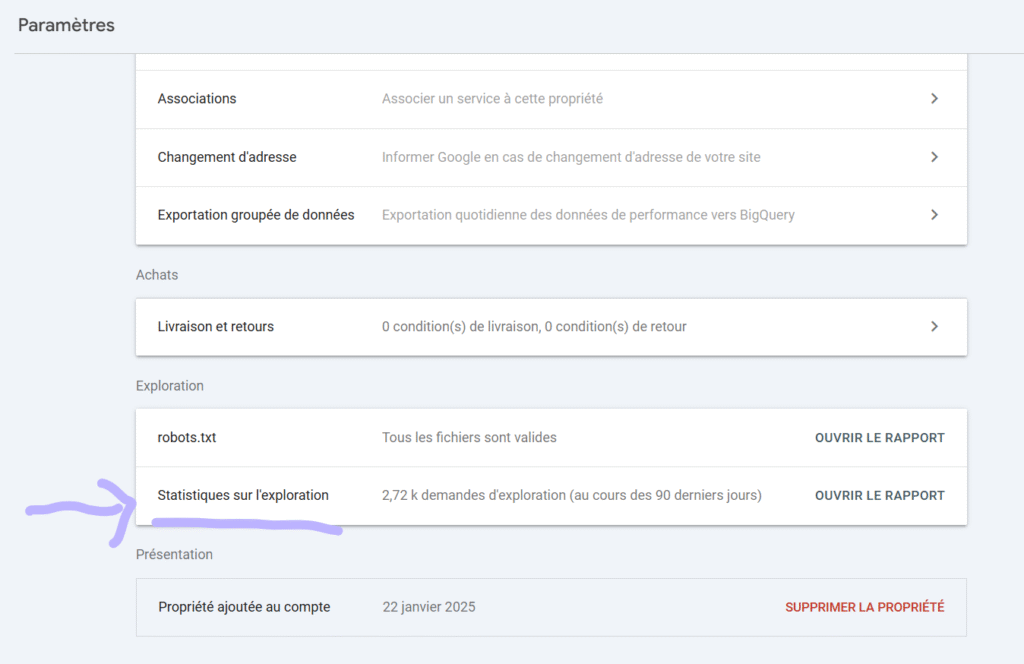
Key metrics to monitor:
- Total crawl requests: How many URLs Google requested (successful or not)
- Total download size: How much data Google fetched
- Average response time: How fast your server responds to Googlebot
Host status details tell you about the technical health of your site from Google’s perspective. These are the infrastructure-level issues that can block crawling entirely:
- Robots.txt fetch: Shows failure rate when Google tries to access your robots.txt. If this fails, Google stops crawling your entire site until it’s resolved.
- DNS resolution: Reveals issues with your domain name resolution. If Google can’t resolve your domain, nothing gets crawled.
- Server connectivity: Tracks when your server was unresponsive. Consistent connectivity issues lead to reduced crawl rates over time.
Crawl request breakdown is where you get the detailed picture of what Google is actually doing on your site. This data helps you understand crawl patterns and identify potential issues:
- Response types: Distribution of status codes (200, 301, 404, 5xx). A high percentage of 5xx errors is a red flag that needs immediate attention.
- File types: What Google is fetching: HTML pages, images, JavaScript, CSS. If JS/CSS makes up a huge portion, your site might be rendering-heavy.
- Crawl purpose: Discovery (finding new URLs) vs Refresh (re-crawling known pages). A healthy site should show both, with refresh dominating for established content.
- Googlebot type: Which crawler is visiting: Smartphone (primary), Desktop, Image, etc. Since Google uses mobile-first indexing, Smartphone should be the main crawler.
And also don’t forget : this report dont show you 100% of googlebot’s visits on your website. From experience it only show 30 to 50% of real googlebot’s visits. If you wanna get all the data you have to collect and analyse your website’s server logs.
2.5 Google Leaks: Content Change Detection
This is where it gets really interesting. According to data from the Google Leaks, we now know that Google’s crawler actively checks if content is different from the last time it visited.

What this means for you:
- Google compares current content to the last crawled version
- This comparison directly influences how often your site gets crawled
- Sites with regularly updated content → crawled more frequently
- Stale sites with no changes → crawled less often
The leaks also revealed that Google uses aggressive caching and throttling mechanisms to make crawling efficient while protecting the servers they crawl.
For example : If Google News fetches a page, the Search team might receive that exact copy 10 seconds later instead of crawling your site again. This shared cache allows Google to ‘see’ updates via one tool even if the other hasn’t visited you yet.
III. Predictive Crawling
Over the past few years, Googlebot has stopped blindly crawling every page it comes across.
“I’ve gotten smarter over the years. Now I try to predict if a page will be worth visiting BEFORE I actually crawl it. Why waste resources on low-quality content?”
3.1 The Shift: From “Crawl Everything” to “Crawl Smart”
The era when Google indexed almost everything you asked it to ? That’s over.
Google doesn’t even want to crawl all pages anymore. The reason is simple : cost optimization and resource efficiency. Crawling the web is expensive, even for Google.
3.2 How Predictive Crawling Works
Google uses machine learning to predict if a page is worth crawling before actually crawling it.
Don’t take my word for it. Here’s what Google employees have said:

“I know that we use machine learning to identify or predict the quality that we’ll get from a crawl. It’s interesting to try to predict how much quality we can get from a specific crawl before it even happens.”
Martin Splitt, Google Developer Relations, November 2020

“My mission [in 2024] is to find a way to crawl even less. […] We’re crawling roughly as much as before, however scheduling got more intelligent and we’re focusing more on URLs that more likely to deserve crawling. ”
Gary Illyes, Google Search Analyst, April 2024
Let that sink in. Google’s explicit mission is to crawl less, not more.
3.3 What Google Evaluates
The prediction is based primarily on:
- Overall quality of previously published pages on your site : If your existing pages are low quality, new pages inherit that reputation
- Historical crawl data : How valuable were previous crawls of your site?
- Site-wide signals : Authority, trustworthiness, technical health
3.4 The QualityRisk Factor
Google essentially calculates a “quality risk” score before deciding to crawl. The logic is:
- Low quality risk → Higher crawl priority
- High quality risk → Lower crawl priority (or no crawl at all)
This means that improving your overall site quality doesn’t just help the pages you optimize, it helps ALL your pages get crawled and indexed.
3.5 Temporal & Content Patterns in Crawling

Google’s research has revealed fascinating patterns about when and what gets crawled. These insights come from analyzing millions of pages and their change dynamics.
Temporal patterns that affect crawl scheduling:
- Midnight peaks: Content changes are most common around midnight (local time), likely due to automated updates and scheduled publishing. Google’s crawler accounts for this.
- Weekday vs weekend: Changes are more likely to happen on weekdays than weekends. The crawler adjusts its scheduling accordingly.
- Category-specific rhythms: Different types of content have different change frequencies. News sites change constantly; corporate pages rarely update. Google learns these patterns per site and category.
These patterns help Google’s crawler make smarter decisions about when to visit your site. If your content typically updates at 9 AM, Google may learn to check around that time rather than crawling randomly throughout the day.
3.6 Change-Indicating Signals (CIS)
Google also uses external signals to decide when to crawl. These are called Change-Indicating Signals (CIS).
IV. The 130-Day Rule: Google’s Hidden Deindexation Threshold
This is a great discovery in recent SEO research, and it comes from Alexis Rylko, who identified this pattern through extensive data analysis.
4.1 The Discovery
After analyzing crawl data from multiple sites using Screaming Frog and the Google Search Console API, Alexis discovered a consistent pattern :
Pages not crawled for 130 days get removed from Google’s index.
That’s it. 130 days without a Googlebot visit, and your page disappears from search results.
4.2 How It Works
Crawl frequency is dynamic and page-specific. Each page on your site has its own crawl frequency that evolves over time based on:
- Content quality
- PageRank (internal + external links)
- Depth in site architecture
- Update frequency
- And most of all : human traffic.
If this frequency degrades to the point where Googlebot hasn’t visited for 130 days, the page gets removed from the index.
Think of it as Google’s housekeeping mechanism, removing pages it considers unimportant to keep the index lean and efficient.
4.4 What Determines Crawl Frequency
Understanding this helps you prevent pages from hitting the 130-day threshold:
Content Quality: High-quality, unique content gets crawled more often. Google’s scheduling is dynamic, when indexing signals indicate quality has improved, crawl demand increases.
“Scheduling is very dynamic. As soon as we get the signals back from search indexing that the quality of the content has increased across this many URLs, we would just start turning up demand.”
Gary Illyes, Google Search Analyst
PageRank: Pages with more internal and external links are considered more important and get crawled more frequently. The deeper a page is in your site architecture, the less important it appears to Google.
Site Architecture: Pages buried deep in your site hierarchy (many clicks from homepage) are seen as less important and may not be crawled frequently enough to stay indexed.
4.5 How to Audit Your Site
Method 1: Screaming Frog + Search Console API
- In Screaming Frog, go to Configuration > API Access > Google Search Console
- Connect your account and enable “URL Inspection”
- Check “Fetch only indexable URLs”
- Run your crawl
- Sort by “Days since last crawl” in descending order
- Investigate any pages approaching 130 days
Free Tool: Visualize Your Deindexation Risk
I built a free tool (in French) that helps you visualize which pages are approaching the 130-day threshold and are at risk of being deindexed.
How it works: Import a CSV export from Screaming Frog (with Google Search Console API data), and the tool shows you exactly which pages need attention.
Access the Tool (Free) →Method 2: Log File Analysis
Ask your hosting provider or developer to export server logs for at least the last 130 days. Cross-reference with your crawled URLs, any crawlable page NOT present in the logs for 130+ days is likely deindexed or at risk.
So if you notice that one of your pages hasn’t been crawled or indexed for, say, at least 110 days and it actually matters to you, it’s time to react.
Update the content, share the page on your social networks to generate traffic, add internal or external links to it. Create activity around that page to attract Googlebot back.
Personally, I build n8n workflows for my clients that call the Google Search Console API and send me an email as soon as a page hasn’t been crawled for at least 110 days. This gives me a few days to react and warn the client before it’s too late.
V. Common Myths Debunked
Let’s clear up some misconceptions I see floating around.
5.1 Myth: Nofollow Links Prevent Crawling
THE MYTH
“Adding rel=nofollow to a link prevents Googlebot from crawling that page.”
THE TRUTH
Google introduced nofollow links to let sites indicate that certain pages shouldn’t count when computing web metrics (like PageRank). But it does NOT prevent Googlebot from crawling those pages.
5.2 Myth: Submitting a Sitemap Guarantees Indexation
The truth: Sitemaps help with URL discovery, but they don’t guarantee indexation. Google still evaluates quality before deciding to index a page.
Submitting a sitemap is like handing Google a list of addresses. Whether Google actually visits and keeps those addresses in its directory depends entirely on their perceived value.
VI. Search Console Insights: Understanding “Crawled – Not Indexed”
If you’ve ever looked at your Search Console coverage report, you’ve probably seen these frustrating statuses. Let me explain what they actually mean.
6.1 “Discovered – Currently Not Indexed”
This means Google knows the URL exists but hasn’t crawled it yet. Google has probably “predicted” that it’s not worth crawling. This is predictive crawling in action, your page was filtered out before Googlebot even visited.
6.2 “Crawled – Currently Not Indexed”
This means Google crawled the page but decided not to index it. Google decided the page isn’t worth indexing. This could be due to thin content, duplicate content, low quality, or simply that Google doesn’t see enough value.
VII. What Google Tracks During Crawl (Google Leaks Insights)
Thanks to the Google Leaks, we now have visibility into what Google actually monitors and logs during the crawling process. This is stuff that was never officially documented.
“I keep detailed notes on every site I visit. Response times, SSL issues, redirect chains… Everything goes in my database and influences how I crawl your site in the future.”
7.1 IP Reputation
Google maintains lists of known spammy IP addresses. If your site is hosted on one of these IPs, it gets rejected for almost all crawls.
Your hosting provider matters. Cheap shared hosting with bad neighbors can hurt your crawlability !!
7.2 Redirect Handling
Google handles redirects very well. They’ve built sophisticated systems to follow and understand redirects but they’re also tracking everything about how you use them.
What Google monitors with redirects:
- Redirect delays: How long each redirect takes. Slow redirects impact user experience and crawl efficiency.
- Chain lengths: How many hops before reaching the final destination. Long chains (3+ redirects) waste crawl budget and signal poor site maintenance.
- Historical patterns: How your redirect behavior has evolved over time. Sudden changes in redirect patterns can trigger additional scrutiny.
Google uses this historical data to calibrate how their crawlers should behave on your site going forward. Sites with clean, fast redirects get treated better than those with messy redirect chains.
7.3 SSL & Security
Bad SSL certificates are logged. Security issues affect crawler behavior. If you have certificate problems, expect reduced crawling.
Clean SSL = smoother crawling.
7.4 Robots.txt Monitoring
Google measures and records everything about your robots.txt:
- Response times
- Error rates
- Changes over time
They keep a small history to understand how their bots should behave. If your robots.txt returns errors (like a 503), Google stops crawling your entire site until it can successfully fetch the file.
7.5 Crawl Error Logging
All crawl errors are logged and used to recalibrate crawl frequency. Consistent errors = reduced crawling.
If Googlebot keeps hitting 5xx errors on your site, it will back off to avoid overloading your servers. The problem is, it might not come back as frequently even after you fix the issues.
VIII. New Revelations: User Data, Spam Scores & Crawl Priority
Recent legal proceedings and leaks have given us unprecedented insight into how Google really decides what to crawl. Spoiler: it goes way beyond just technical factors.
Before we dive into the recent revelations, let’s put everything together. Here are the 5 critical factors that influence Google’s crawl decisions in 2026 :
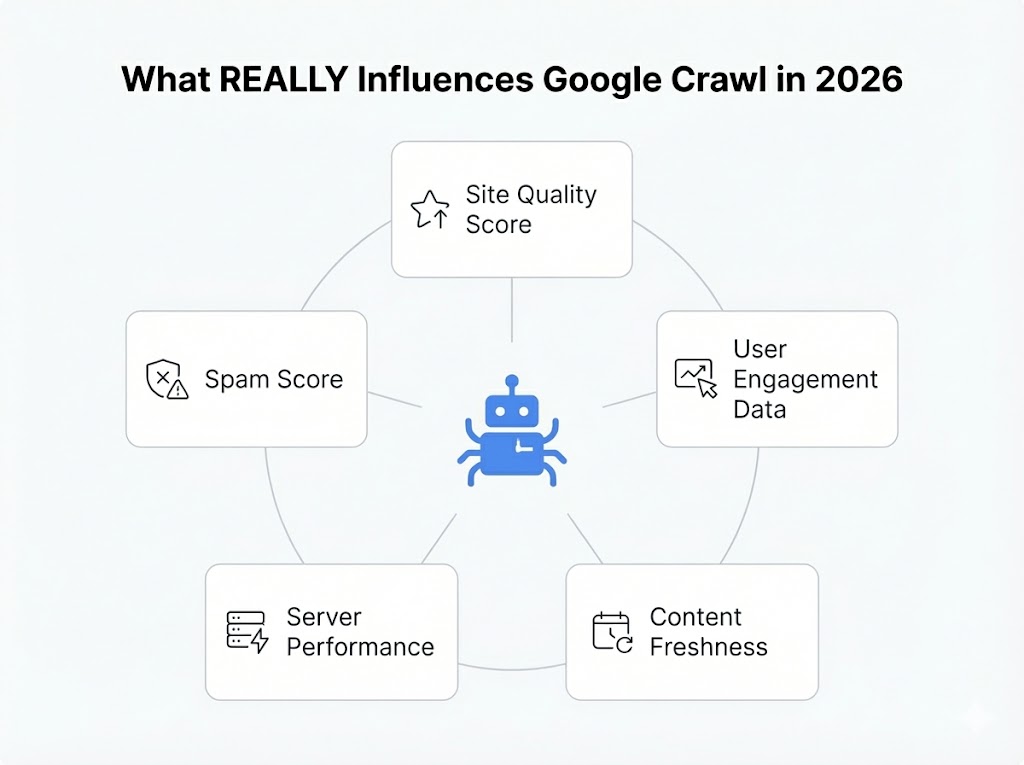
Now let’s explore the two most surprising ones that emerged from legal proceedings …
8.1 The DOJ Antitrust Trial Revelation
During the DOJ antitrust trial against Google, something fascinating emerged. Court documents revealed that Google doesn’t just look at your site’s technical health when deciding crawl priority, they also look at how real users interact with your site.
According to DOJ findings:

This is huge. It means that user engagement signals directly influence whether Googlebot prioritizes your pages for crawling.
What this means practically:
- Pages that users engage with get crawled more frequently because Google sees ongoing interest
- Pages with poor engagement metrics may see reduced crawl frequency over time
- New sites with no user data start at a disadvantage, Google has nothing to base crawl priority on except technical signals and site reputation
This creates a virtuous (or vicious) cycle: popular content gets crawled more, stays fresh in the index, and maintains rankings, while ignored content slowly fades from Google’s attention.
8.2 Spam Scores and Crawl Frequency
Google assigns spam scores to websites, and these scores directly affect how often your site gets crawled.
Think of it like a trust rating. Every site has a spam score based on various signals:
- Link profile quality: Are you associated with link schemes or spammy networks?
- Content patterns: Do you have thin, duplicated, or auto-generated content?
- User behavior signals: High bounce rates, pogo-sticking, low engagement
- Historical violations: Past manual actions or algorithmic penalties
- Neighborhood analysis: What other sites share your hosting IP or link to you?

IX. ⚠️ The Geoblocking Trap
Google crawls the web almost exclusively from the United States (typically from California, with IP addresses starting with 66.x.x.x). If you use geoblocking to restrict your site to a specific country (e.g., only allowing French IPs), Googlebot will receive a 403 error or a timeout.
While Google has a few localized IPs for high-value content, they are extremely ‘frugal’ with them. Rule of thumb: never geoblock Googlebot if you want to stay indexed.
X. Conclusion
Crawling is the foundation of everything in SEO. Without it, nothing else matters.
Here’s what you should take away from this :
Key Takeaways
Google now decides if your page is worth crawling BEFORE visiting. Site reputation matters more than ever.
Pages not crawled for 130 days get deindexed. Monitor your crawl frequency and address at-risk pages.
Your site-wide quality affects crawling of ALL pages, including new ones. Clean up low-quality content.
Google detects content changes. Regular, meaningful updates keep you in the crawl rotation.
The web is getting bigger, but Google’s appetite for crawling is getting smaller. The sites that understand this shift and optimize accordingly will have a significant advantage.
If you found this useful, bookmark it and share it with someone who needs to understand crawling better.
That’s all for today. Bye !

Ian Sorin is an SEO consultant at Empirik, a digital marketing agency based in Lyon, France. With a deep passion for understanding how search engines work under the hood, he specializes in technical SEO and helping websites get discovered, crawled, and indexed effectively.





