
Hiding Keywords to Rank Higher: What a Google Patent Reveals About Keyword Prominence

Hiding Keywords to Rank Higher: What a Google Patent Reveals About Keyword Prominence
Stuffing hidden keywords? A patent says it backfires.
 Ian Sorin
April 15, 2026
8 min read
Ian Sorin
April 15, 2026
8 min read
8 min read
Hey, it’s Ian!
For years, a certain category of SEO advice has been circulating: force your target keywords everywhere you can, even if users never see them. Stuff your image alt attributes with keyword lists. Add a paragraph of tiny, light-gray text at the bottom of the page. Use a white font on a white background. Hide a keyword block behind a collapsible section that no one opens.
The logic behind it? Google crawls the raw HTML, not what the user actually sees. So technically, the words are “there.”
But here is the thing: Google knows the difference between a keyword placed prominently for real users and one buried where no human would ever look. And we now have a patent that shows, in technical detail, how that distinction is encoded into one of their systems.
Today I want to walk you through that patent, explain the specific mechanism that matters, and give you a clear picture of what it means for how you place keywords on a page.
- Google Patent US11797626 describes a system that scores keywords based on where they appear on a page, not just how often
- Keywords in titles receive higher quality scores than those in body text, metadata, or inconspicuous locations
- The patent explicitly removes keywords found “only in metadata, or in inconspicuous locations” from its scoring pipeline
- This patent covers search filter generation, not ranking directly. But the underlying philosophy is consistent with everything we know about prominence signals
- The practical takeaway: hiding keywords does not fool Google. It signals that those terms are low-value
The Patent: What It Is (and What It Is Not)
Let’s start with context, because it matters for intellectual honesty.
The patent in question is US11797626B2, titled “Search result filters from resource content”, filed by Google LLC and granted in October 2023. The inventors are Ian MacGillivray, Kaylin Spitz, Selena Sunling Yang, Varun Jasjit Singh, Emma Persky, and Yonatan Erez.
The official subject of this patent is the automatic generation of search result filters: those clickable refinement pills that sometimes appear below the search bar in Google, letting you narrow results by subtopic. The problem the patent solves is that these filters were previously either manually curated (slow, limited) or entirely absent. The new system generates them dynamically from the content of the pages that are actually ranking for a given query.
So: this is not a ranking patent. It does not describe PageRank, it does not describe the core indexing pipeline.
But here is why it matters for anyone thinking about keyword strategy: to determine which keywords deserve to become filters, the system has to evaluate keyword quality. And the way it measures quality is directly tied to where the keyword lives on the page.
The Scoring Mechanism: Location Is Everything
This is the part of the patent worth reading carefully.
The system works in two phases. First, it extracts a broad set of candidate keywords from the content of pages that responded to a search query. Then it filters and scores those candidates to decide which ones are worth surfacing as filters.
The scoring step (described as Step 506 in Figure 5 of the patent) is defined as follows:
Direct quote – US Patent 11797626
“For each candidate query filter in the set of candidate filters, the filter subsystem determines quality scores for the candidate query filters based on the locations of the candidate query filters in the resources.“
Location-based scoring. Not frequency alone. Not semantic relevance alone. Where the word appears.
The patent then gives a concrete example to illustrate the hierarchy. I’ll let it speak for itself:
Direct quote – US Patent 11797626
“A candidate query filter that appears in a prominent position of a resource, such as in the title of a resource, may be assigned a higher quality score than a different candidate query filter that appears in meta data associated with the resource.”
And then this, which is probably the most revealing sentence in the entire patent from an SEO perspective:
Direct quote – US Patent 11797626
The system removes candidate keywords that “only appear in metadata, or in inconspicuous locations in the corresponding responsive resource.”
They are not simply scored lower. They are excluded.
Let that sink in. The system does not just penalize keywords found in hidden or peripheral locations. It removes them from consideration entirely.
The Prominence Hierarchy
Putting together everything the patent describes, here is the implicit hierarchy for keyword quality scoring:
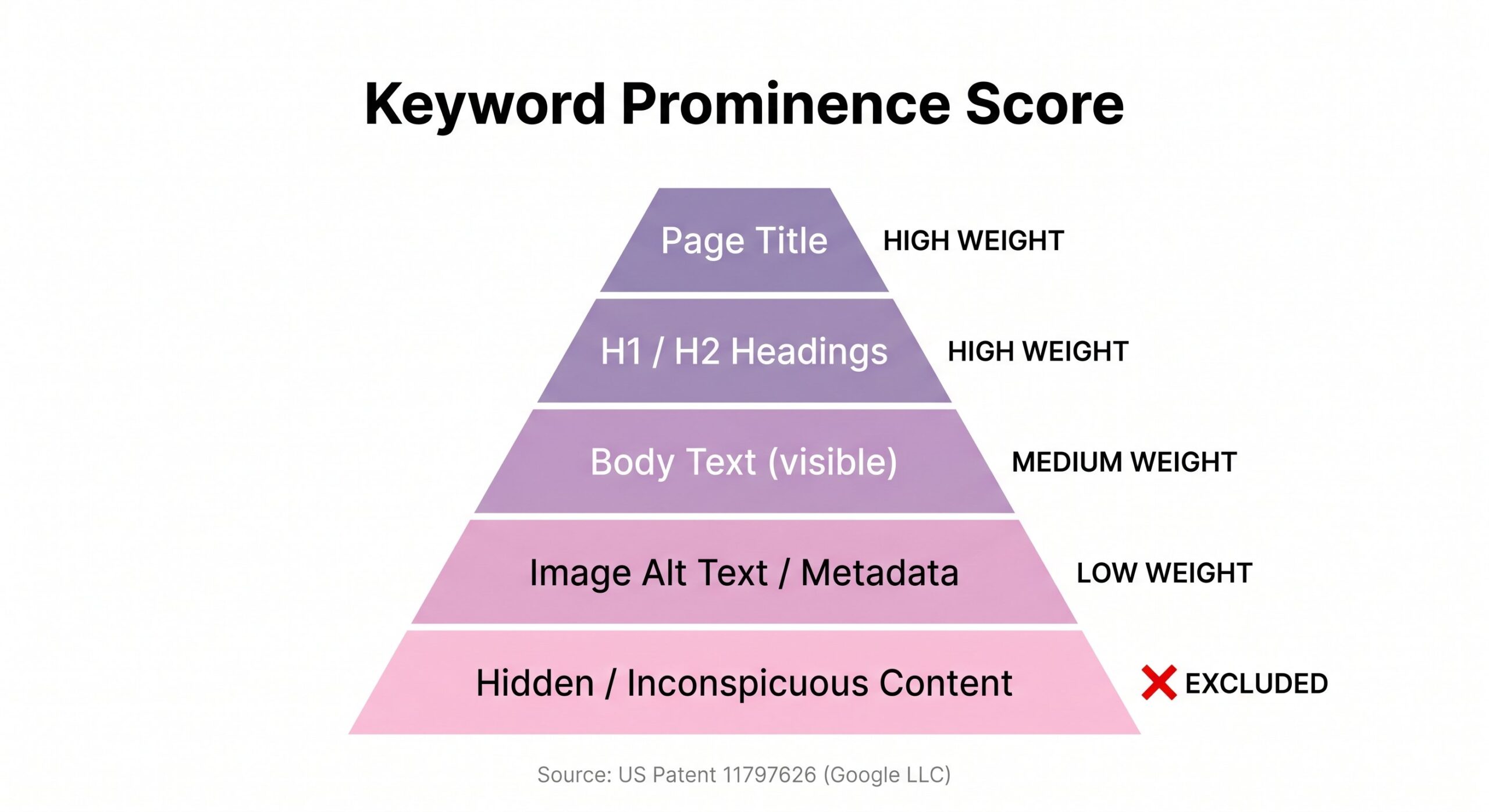
| Location | What the patent says | Signal weight |
|---|---|---|
| Page Title | “Prominent position” – explicitly cited as the reference for high quality score | High |
| H2 / Body sections | “Body sections subordinate to the titles” – cited in the patent example, positioned below title placement | Medium |
| Metadata | “Meta data associated with the resource” – explicitly compared unfavorably to title placement | Low |
| “Inconspicuous locations” | Explicitly named as grounds for exclusion. Not scored lower: removed entirely from the pipeline. | Excluded |
Why This Goes Beyond Search Filters
I want to be precise here. This patent is specifically about filter generation, not about ranking. I am not claiming it directly controls your position in the SERP.
But here is the broader point worth making: this patent reveals a scoring philosophy that Google has explicitly built into at least one of their systems.
The idea that keyword prominence matters more than raw frequency is not new in SEO theory. What is new here is that we have a patent where Google engineers formally encode the rule “inconspicuous location = excluded.” This is not an algorithm trying to figure out intent. This is engineers explicitly writing a rule that says: if a keyword is hidden from the user, it does not count.
That design decision does not exist in a vacuum. It reflects how Google thinks about the relationship between content and keywords across their systems. The filter generation pipeline, the ranking pipeline, the quality assessment pipeline: they all share engineers, design reviews, and architectural principles. When Google builds location-based keyword scoring into one system, it tells you something meaningful about the overall philosophy.
💡
The useful mental model: a keyword placed where no real user would read it is not just invisible to humans. Google has systems designed to identify exactly those keywords and discount them. The “Google only reads HTML” assumption was never accurate, and this patent is one more piece of evidence for that.
Common Tactics, Judged by Patent Logic
Let’s apply the patent’s framework to the tactics that still get recommended in some corners of the SEO world.
What This Means in Practice
None of this should be surprising if you have been following Google’s quality signals for the past ten years. But having it written in a patent, by Google engineers, in a technical specification, is different from having it as a “best practice” from an SEO blog.
The practical implications are straightforward:
- Stop optimizing for the crawler. The systems Google builds are explicitly designed to discount content that was placed for crawlers rather than users.
- Keyword placement quality beats keyword placement quantity. One mention in a title is, by this patent’s logic, worth more than ten mentions buried in a footer or stuffed into alt attributes.
- If a human would not read it, Google probably discounts it. That is the underlying principle across this and many other Google systems.
The idea that you can game keyword signals by hiding terms in places users never see was always going to have a limited shelf life. What this patent shows is that Google has actively engineered solutions to exactly this problem, and those solutions work by evaluating where a keyword sits in the page, not just whether it is present in the HTML.
As always, the answer is boring but true: write content where keywords appear naturally in prominent positions because the content genuinely covers those topics. That is what the patent rewards.
That’s all for today. Bye!
Key Takeaways
Google’s system assigns quality scores to keywords based on where they appear in the page, not just how often.
Keywords found only in inconspicuous locations are removed from the pipeline entirely, per the patent’s explicit wording.
The patent uses the page title as the reference example for high quality score. One well-placed title keyword outweighs many hidden ones.
This patent is about filters, not ranking. But the design philosophy (prominence = weight) is consistent across Google’s approach to content quality.

Ian Sorin is an SEO consultant at Empirik, a digital marketing agency based in Lyon, France. With a deep passion for understanding how search engines work under the hood, he specializes in technical SEO and helping websites get discovered, crawled, and indexed effectively.





