Is Google’s NavBoost already obsolete? What this research paper tells us about the future of click data

Is Google’s NavBoost already obsolete? What this research paper tells us about the future of click data
What a research paper says about the future of click data.
 Ian Sorin
November 21, 2025
6 min read
Ian Sorin
November 21, 2025
6 min read
- The Research – Chinese Academy of Sciences + Baidu researchers compared LLM annotations vs. user clicks for training ranking models
- Key Finding – Neither wins across the board – clicks perform better on high-frequency queries, LLMs excel on medium/low-frequency queries
- Why It Matters – Clicks capture authority signals, LLMs capture semantic matching – and they’re complementary
- Google’s NavBoost at Risk? – Maybe not. The research suggests the best approach is combining both signals, not replacing one with the other
Hey 👋
Today we’re diving into a research paper from Baidu’s team that asks whether LLMs could actually replace user clicks for training ranking models.

Hey, Is NavBoost Dead?
Google has been collecting user click data for over two decades. NavBoost, one of their core ranking algorithms leaked in 2024, relies heavily on this behavioral data to understand what users actually find relevant. It’s one of Google’s biggest competitive advantages – or at least it was.
Because here’s the thing: what if you could train equally good (or better) ranking models without needing millions of users clicking on search results? What if a large language model could just… tell you what’s relevant?
That’s exactly what researchers from the Chinese Academy of Sciences and Baidu Inc. set out to investigate in their paper “Can LLM Annotations Replace User Clicks for Learning to Rank?”
The answer? It’s complicated. And actually pretty interesting for anyone working in SEO.
What the Research Actually Found
The baidu team ran extensive experiments comparing ranking models trained on:
- Real user click data
- LLM-generated relevance annotations
They tested on both a public dataset and Baidu’s internal search data.
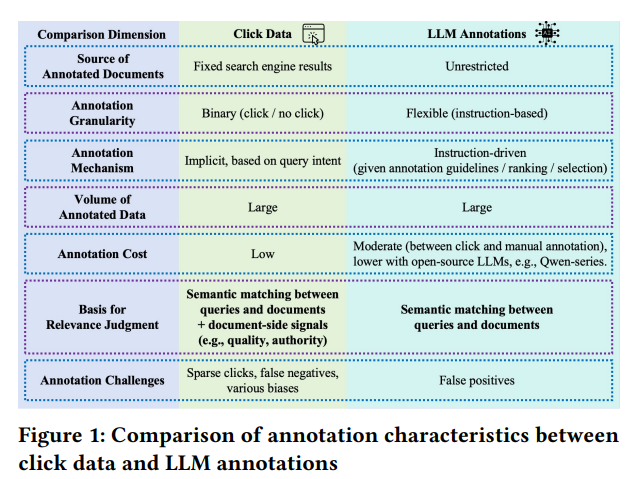
The Core Differences
According to the paper, click data and LLM annotations capture fundamentally different signals:
Click Data Captures
• Semantic matching between query and document• Document-level signals (authority, quality, trust)
• Works best when there are already many relevant results (high-frequency queries)
LLM Annotations Capture
• Strong semantic relevance between query-document pairs• Better at distinguishing relevant from non-relevant content
• More effective on medium and low-frequency queries where semantic matching matters more
The researchers tested several annotation strategies with LLMs. The winner? ListAnn – feeding the LLM a complete list of candidate documents at once and having it annotate based on explicit guidelines. This outperformed both pointwise annotation (one document at a time) and having the LLM directly rank results.
Here’s one of the prompts they used for the ListAnn strategy:
“Assume someone has entered the query [query] into a search engine, the search engine returns the following {doc_num} unordered web pages:
[list of documents with titles, snippets, and domain names]
Please evaluate the relevance of all web pages at once according to the annotation criteria (0 to 4). Each web page is composed of a title and content, and the domain name is also provided.”
The Frequency Factor: Where Each Approach Wins
This is where it gets really interesting for SEO.
The researchers split queries into three buckets based on search volume. To clarify what these frequency categories actually mean:
- High-frequency queries: Popular search terms that get searched repeatedly (think “iPhone 15”, “weather Paris”, “best running shoes”). These queries have abundant click data because thousands or millions of users search for them regularly.
- Medium-frequency queries: Terms with moderate search volume – searched regularly but not at massive scale (like “iPhone 15 battery drain issue” or “trail running shoes for overpronators”).
- Low-frequency queries: Long-tail, specific searches that might only happen a few times per month (like “iPhone 15 Pro Max battery draining fast on iOS 17.3 after latest update”). These are the queries where Google has limited or no historical click data.
The performance patterns were striking:
High-Frequency Queries
• Click-supervised models: ✅ Better performance• LLM-supervised models: ❌ Underperformed
Medium & Low-Frequency Queries
• Click-supervised models: ❌ Underperformed• LLM-supervised models: ✅ Better performance
Why? The paper suggests that on high-frequency queries, search engines have already optimized to return relevant results. At this point, distinguishing the best result requires document-level signals like authority and quality – which clicks capture well but LLMs struggle with.
On lower-frequency queries, the challenge is more about understanding semantic relevance in the first place. LLMs excel here.
The Document-Level Signal Problem
The researchers went deeper by introducing different types of ranking features:
- Query-document level features: BM25, TF-IDF, language model scores
- Document-level features: PageRank, domain authority signals, URL structure
When they added these features to models trained on each annotation type, they found something revealing:
For click-trained models:
- Adding query-document semantic features → significant improvement
- Adding document-level features → minimal improvement
For LLM-trained models:
- Adding query-document semantic features → minimal improvement
- Adding document-level features → significant improvement
This confirms that click-trained models already captured document-level signals but were weaker on pure semantic matching. LLM-trained models had the opposite problem.
Can LLMs Actually Distinguish Relevant from Irrelevant?
Here’s a critical question the researchers addressed: Most search results returned are already somewhat relevant. Can these models actually tell the difference between a relevant and a truly irrelevant result?
They tested this by introducing “true negative” examples – completely irrelevant documents – into both training and test sets.
Results:
- LLM-supervised models: Maintained strong performance, proved they could distinguish relevant from irrelevant
- Click-supervised models: Performance dropped significantly, suggesting they were weaker at this fundamental distinction
However, when true negatives were added to the training data for click-supervised models, their ability to distinguish relevance improved – and they even got better at ranking among relevant results.
What This Means for Google and NavBoost
So back to the original question: is NavBoost obsolete ?

Short answer: Probably not. But it might need a hybrid approach.
The research suggests that pure click data has limitations, especially on:
- Long-tail queries (where Google has less behavioral data)
- New queries (where no click history exists yet)
- Semantic understanding (where LLMs excel)
But click data remains valuable for:
- Capturing implicit quality signals (authority, trust, freshness)
- High-frequency queries where semantic relevance is already solved
- Understanding user behavior patterns that LLMs can’t infer from content alone
The implication: Search engines with extensive click data (Google, Bing) still have a major advantage, but emerging competitors using LLM-based relevance evaluation could potentially close the gap faster than we thought – especially on long-tail queries.
For Google specifically, we could speculate that they might already be doing something similar to the hybrid approaches described in this paper. We know they use both:
- Behavioral signals (NavBoost, user engagement metrics)
- Semantic understanding (BERT, MUM, and now Gemini models)
This research provides a framework for understanding why combining both signals might be optimal, and how to do it effectively based on query characteristics.
Final Thoughts
This research doesn’t prove that click data is dead. It proves that it’s not enough on its own – and neither are LLM annotations.
The future of search ranking might not be about choosing between behavioral data and AI-generated relevance judgments. It’s about intelligently combining both.
And here’s something crucial for SEOs to understand: search engines are incredibly complex systems where context is everything. This research confirms what many of us suspected – there’s no universal rule that applies to all queries.
For some queries (high-frequency, competitive terms), user clicks might play a significant role in rankings. For others (long-tail, semantic queries), click manipulation would likely have zero impact because the algorithm is relying on completely different signals.
Anyone telling you “clicks always matter” or “clicks never matter” is oversimplifying. The reality is nuanced: it depends on the query type, the search volume, the competitive landscape, and how the algorithm decides to weight different signals for that specific context.
Google’s massive click data advantage isn’t going away. But competitors who leverage LLMs effectively for long-tail queries might be able to compete more effectively than the click data moat would suggest.
One thing’s certain: the assumptions we’ve had about how much click data matters for ranking are being challenged. And that’s worth paying attention to.
Research paper: “Can LLM Annotations Replace User Clicks for Learning to Rank?” by Lulu Yu, Keping Bi, Jiafeng Guo (State Key Laboratory of AI Safety, ICT, Chinese Academy of Sciences) and Shihao Liu, Shuaiqiang Wang, Dawei Yin (Baidu Inc.) – 2025

Ian Sorin is an SEO consultant at Empirik, a digital marketing agency based in Lyon, France. He keeps a close eye on research papers about LLM manipulation, because understanding how these systems can be gamed isn’t just academic curiosity, it’s becoming critical for SEO. As search engines integrate more AI into their results and RAG systems proliferate across the web, knowing the attack vectors helps predict where the ecosystem is heading. He builds tools to automate the tedious parts of SEO, runs experiments on his own projects, and digs into research to stay ahead of how AI is reshaping search.




